
In a previous article, we looked at the overall architecture of our logging system and how it has evolved. In this article we will look at the frequent problems that we have to deal with when interacting with processes on different instances, which we also have to deal with in the process of constructing an ideal logging system. But we will also cover the main topic of our article - why your application should not be responsible for delivering logs.
When transferring data from one host to another host or a program on one instance to a program on another instance, we face with the concept of interprocess communication (IPC) in Linux.
TCP or stream-sockets in action
In order for one program to transmit a message to another program, an abstraction in the form of ports was invented. Knowing the TCP address of the computer, we know where to send, and knowing the port to which we can send messages, assuming that the program "owning" this port can pick up this data from there. Thus, we abstract from specific program identifiers.
Another useful abstraction in linux that makes life easier for a programmer is a file. A device, a file on a disk or a network - you will always work with the file abstraction. In case of network interaction, you will work with sockets - special "files" intended for exchanging messages on the network.
There are two types of sockets: stream-socket and datagram-socket.
- Stream-socket can be represented as an entry / exit point of an endless river of bytes (note that the byte sequence, otherwise it will not be a stream).
- Datagram-socket can be thought of as your personal mailbox, which is ready to receive letters or telegrams (a sequential and limited set of bytes), but the number of such messages cannot exceed the size of your mailbox.
The guarantees that follow from the definition of stream-socket can be provided both at the local level (UNIX domain) and at the network level (IPv4 or IPv6 domain). At the network level, such guarantees are implemented by the TCP or Transmission Control Protocol. I would like to focus on the fact that the type of socket is more important here, and not the domain (UNIX or IPv4/IPv6) in which it works.
A protocol is a standard that describes the format and interaction of data transfer. For example, sending ordinary letters via post office can also be called a transfer protocol - on such letters we need to indicate the sender and recipient in a certain format, and also pay for the sending, etc.
Having created the stream socket (linux api function socket) and port, we need to somehow "connect" them (linux api function bind), and then we are ready to start receiving messages from the clients that transmit them (linux api function listen).

The Linux API function is an available C language function that allows you to "officially" perform actions in user space linux using the Linux kernel system resources and services. Interpreted languages such as python and ruby can wrap C language functions in their own libraries and classes, providing greater convenience and development speed with such functions.
After this stage, the client can also create a stream socket (linux api function socket) and then connect (linux api function connect).

Usually, at this point, illustrations or explanations of how the 3-way handshake and further details of establishing a connection between programs begin to appear. But, as a rule, such details become relevant when there are any errors in establishing a connection or in the process of information transfer between the clients.
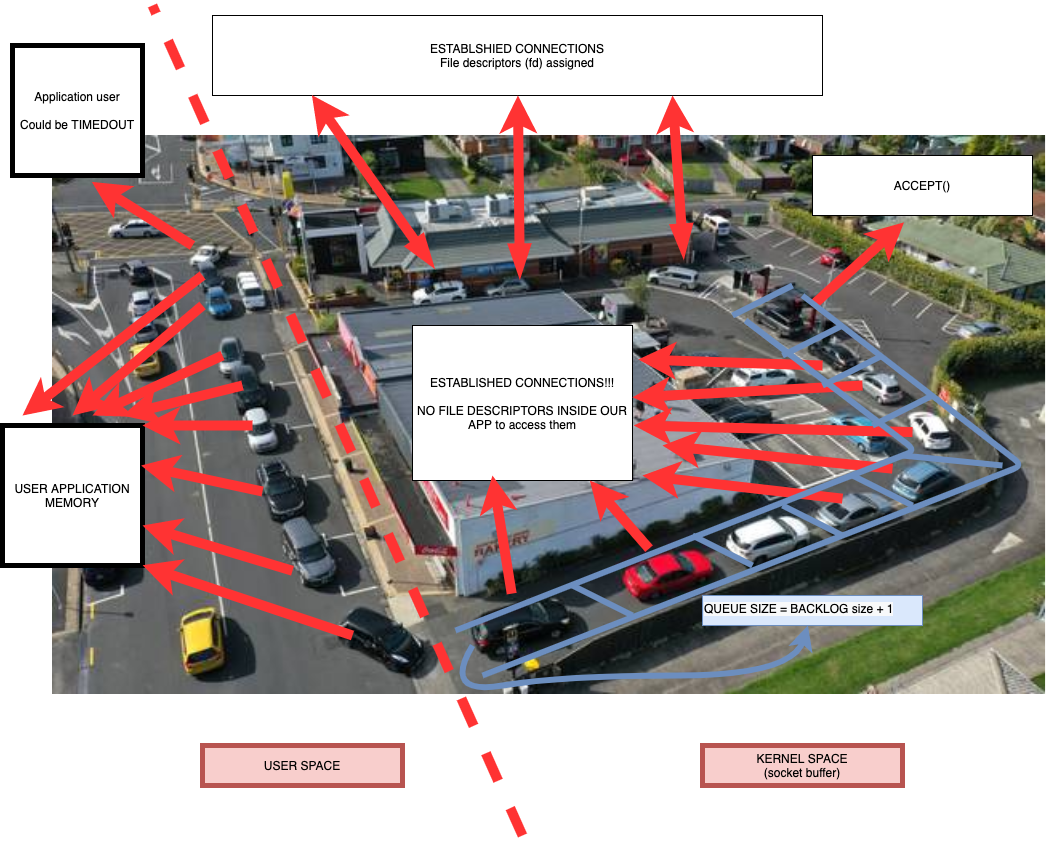
After the connection is established, we can start sending messages. But here, our next question awaits - what to do if the message is lost and who guarantees its' delivery? If linux guarantees delivery of a message after it is received from the application, then it needs a buffer for the delivery time, in case linux needs to send them again in case of loss. The same is true in the opposite case, when a part of a message comes and the receiving application has not yet managed to process it. Thus, we need a buffer for receiving and sending both on the sending side and on the receiving side.

In the figure, we see that each client socket creates a buffer for receiving and sending at the Linux level. But a curious developer immediately has a lot of questions:
- what is the size of the socket buffer
- what happens when the buffer size is exceeded
- server side
- client side
- Is the buffer on the listening socket shared, or is it as separate as on the clients?
- whether it is necessary to increase the size of such buffers and how large they should be made
We will conduct an empirical experiment on ruby (yes, best language in the world) and try to find the answers.

In the lower left corner we can see Socket Stat ( ss) for all stream sockets that are connected to port 19_019 (note also that netstat is showing at the same time). What we can find out when viewing this window:
- LISTEN socket
*: 19_019in the Send-Q column shows the size of the backlog (the max number of connections waiting to be accepted - as we can see from the Recv-Q column, it can acceptbacklog + 1the number of waiting ESTABLISHED connections). Once again, I want to note that the connection has already been established (!) - the client can send messages there (imagine that you were allowed to queue to make an order, but you have not yet made payment) - After connecting the client to the server, we see two ESTABLISHED sockets - the server
127.0.0.1:19019 -> 127.0.0.1: 37242and the client127.0.0.1:37242 -> 127.0.0.1: 19019(we are the server and client create on one instance). - The client and server socket have their own Recv and Send buffers
- When the Recv buffer overflows on the server, the client buffer holds the rest of the data in the local Send buffer.
And another important point that I want to focus on is that the data in the buffer belongs to the operating system, and not to our process (!), which means that we will not see memory consumption at the process level until we start taking data from there.
Let's see what happens to the client when it tries to connect when the queue of connections waiting to be accepted is full

As we can see, it is blocked and the connection is in the SYN-SENT state (our client application does not know this). After accepting the first socket, we get the first messages from the buffer (!)
It is important that socket1 for a very long time “thinks” that the data has been sent, although practically all this time they were in the linux buffer both on the server and on the client (!).
Is it true that the buffer is 981_788 bytes? Let's send the message again and see, after picking up the message that is still in the buffer.

After further experiments, we see that the buffer size increased and reached a size of 5_901_199 bytes. More than 5 MB is in the linux buffer, which are waiting for their turn to be processed by the application. And if there will be 1_000 of such connections?
You can also make sure that if the buffer is empty, the connection is blocked until messages appear in it (here golang developers can recall go-channels - a very similar behavior).
Thus, we see the following default behavior of tcp in modern linux:
- the buffer size automatically increases to a certain limit from the initial level
- there is a limit on the number of pending connections
- after the buffer is full (no matter how big it is), the sender is blocked, which means that sender don't have an ability to send messages to the server
TCP in logging
This TCP behavior raises server connectivity issues.
- How to handle when the clients cannot connect and send logs
If a client “receives” connection error (as in scenario above), then another chain of questions arises:- How long for should a client try to reconnect?
- What should a client do if it cannot connect?
- Do not send logs or
- Do not launch / crash the application?
- How do we know that our logs are not sent if we do not send them?
A lot of questions. And all of this led me to an analogy from everyday life that describes the behavior of TCP in this extreme situation.
Imagine that your car is an analogue of a client socket and you plan to visit your favorite drive thru restaurant. As soon as you left the roadway, you established a connection (established connection, 3-way handshake successful) and got into the backlog queue. When your turn to place an order comes (connection accepted), you begin to exchange messages with the staff – your order, your order changes, payment – and with their managers if something goes wrong.
Usually everything is fine, as long as the restaurant copes with the flow of requests, but if the waiting queue is full (backlog queue), then all other connections are built in anticipation of the opportunity to get into the restaurant queue (all cars are on the roadway waiting for the opportunity to drive in).
If the waiting time in the roadway queue is exceeded and the connection cannot be established, the balancer (in our analogy, this may be the traffic controller at the intersection) can change the route for sending requests to another server (in our analogy, the restaurant).
As we discussed in the previous article, you can increase the availability of logging by introducing a balancer that can redirect connections to the instance that is less loaded with connections, but then you need at least two such instances, and if you do not have idle hardware waiting, then this triggers additional costs.
If you still managed to connect, then as we saw earlier, the client does not know whether the server started processing it or not. What happens when the size of the system socket buffer is exhausted? (you can imagine that all the passengers of the car begin to tell the driver what they want to order). What to do with messages that are waiting to be sent? Create a buffer for sending within the application? How big do it? What to do when it ends? flood?
In the worst case, your application will “crash”, and in the best, you simply lose the logs.
In one of the intermediate logging options, in one day we were able to switch to parallel logging to files.

and one day we saw that for some reason the logs did not come to Logstash, which was written in a separate file (the picture is the bottom and color).
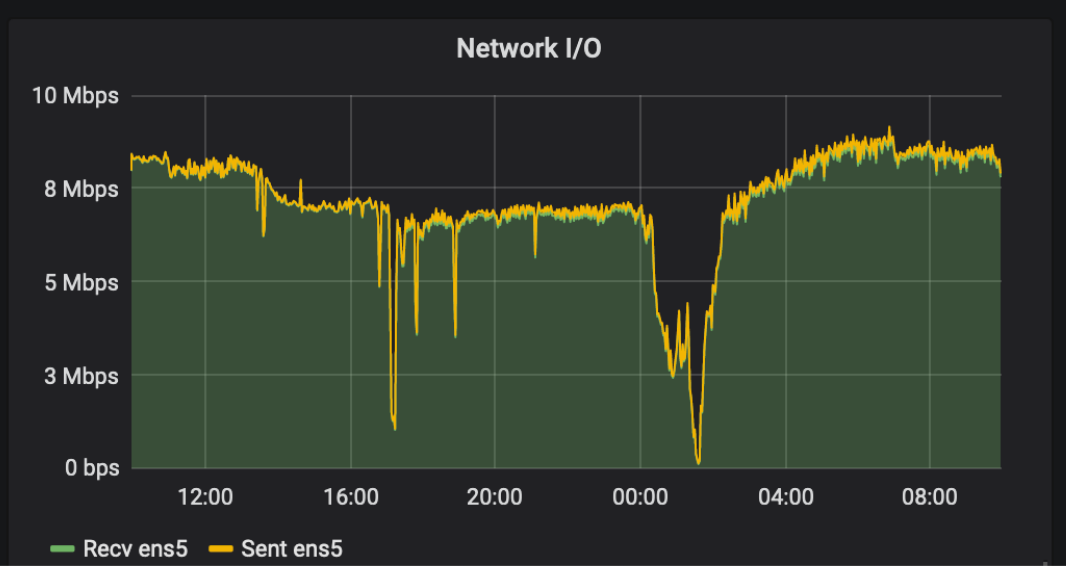
After studying the load in the last day, we saw a spike-load, which did not affect the application, but as we guessed, it affected the delivery of logs via tcp.
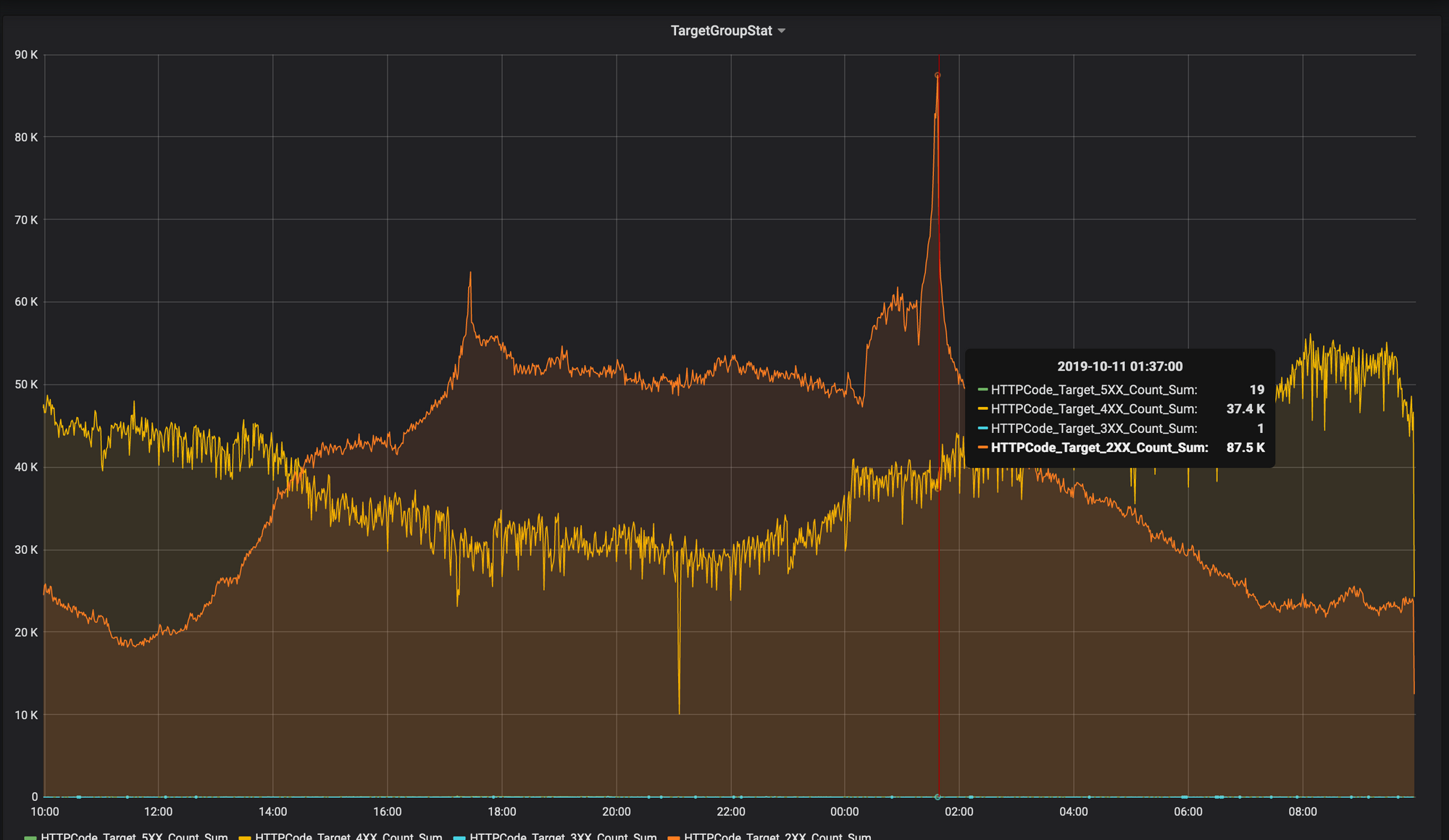
Since the number of threads processing accept connections in Logstash is limited, as is the speed with which Logstash can process such messages, sooner or later your application logger will have to decide what to do with messages that are accumulated in the logger buffer. The choice here is not big - erase the intermediate storage of logs (applications) after a certain size, and try to connect to the server to send new messages (if it is no longer possible to connect). Or maybe look at UDP?
UDP or datagram-socket in action
Datagram-socket differs from stream-socket in several key aspects:
- messages are transmitted, not a stream of bytes
- message order is not guaranteed
- message delivery is not guaranteed
To begin, let's see how UDP messages are transmitted between two virtual instances - HOST1 (server role) and HOST2 (client role):
-
First, create our
server(receiving socket) using thesocket()function on the server instance HOST1 -
Then using the explicitly selected port (
19_019in our case), we indicate to the socket on which port we will receive messages using thebind()function -
We also act on the client instance HOST2, creating the client socket
client1using the same functionsocket()3a. backup step (read on)
-
After that, we can send messages from
client1to ourserverusing thesendtofunction. Please note that during the execution of this function a random port was also created (40_163in the example below), which can be used for further communication of the server with the client (!) -
Using the function
recvfrom()we can receive messages on ourserver, which immediately returns both the message and the sender address of this message(!) -
Having skipped the creation of the client socket (client2) on the server side (HOST1) in the figure below and using the sender address from step 5, we can send a message to our client1 on another socket (!)

Let's see how this happens in our beloved ruby

But what if we want to limit the reception of messages on clients (so that only the server can send messages to our clients)? In this case, in step 3a, we can use the connect() function, which will restrict the reception of messages similar to those we did in step 6, and allow the receipt of such messages only from the server socket. (when viewing the screencast, pay attention to the packets to unknown port received counter in the lower left corner. When we try to send a message from the server socket to the established connection with the client - a hint, it will increase from 99 to 100)

What restrictions does our socket have?
In the screencast below, you can see that it is possible to send a message of no more than ~ 65k bytes in length, in case of exceeding the length, an error pops up, and in case of a buffer overflow on the server side, we see an increase in the RcvbufErrors counter (as well as packets receive errors).

If the socket buffer is full, the message will simply be discarded.
It is also worth paying attention to several important nuances.
- in the socket buffer we see some additional bytes of information - sending a message of one byte in the buffer we see much more than one byte (about 768 bytes)
- in
recvfromwe always indicated that we want to get 1 first byte regardless of the length of the received message in the buffer. Despite the length of the message that was sent to us (an analogue from real life - a letter), we will see only the length that we explicitly indicated when it was received (!) (The analogue of the fact that we cut out part of the message with scissors and decided to read only part of the message, which was in it)
It is also interesting what will happen if our program restarts - can the new socket accept requests from old clients, including those that previously made connect()?
UDP in logging
A deeper understanding of the operation of datagram sockets helped us understand why sometimes we have seen Nginx request logs, but did not see these request logs inside our docker-application. Due to lack of a large number of errors in the Nginx logs, we understood that the ruby-application inside docker-container was working correctly, but the docker-container logs for a specific user were not complete. It became clear that we had to search for an answer inside UDP and for a start we set up it's monitoring to visually see the errors that appear due to buffer overflows.
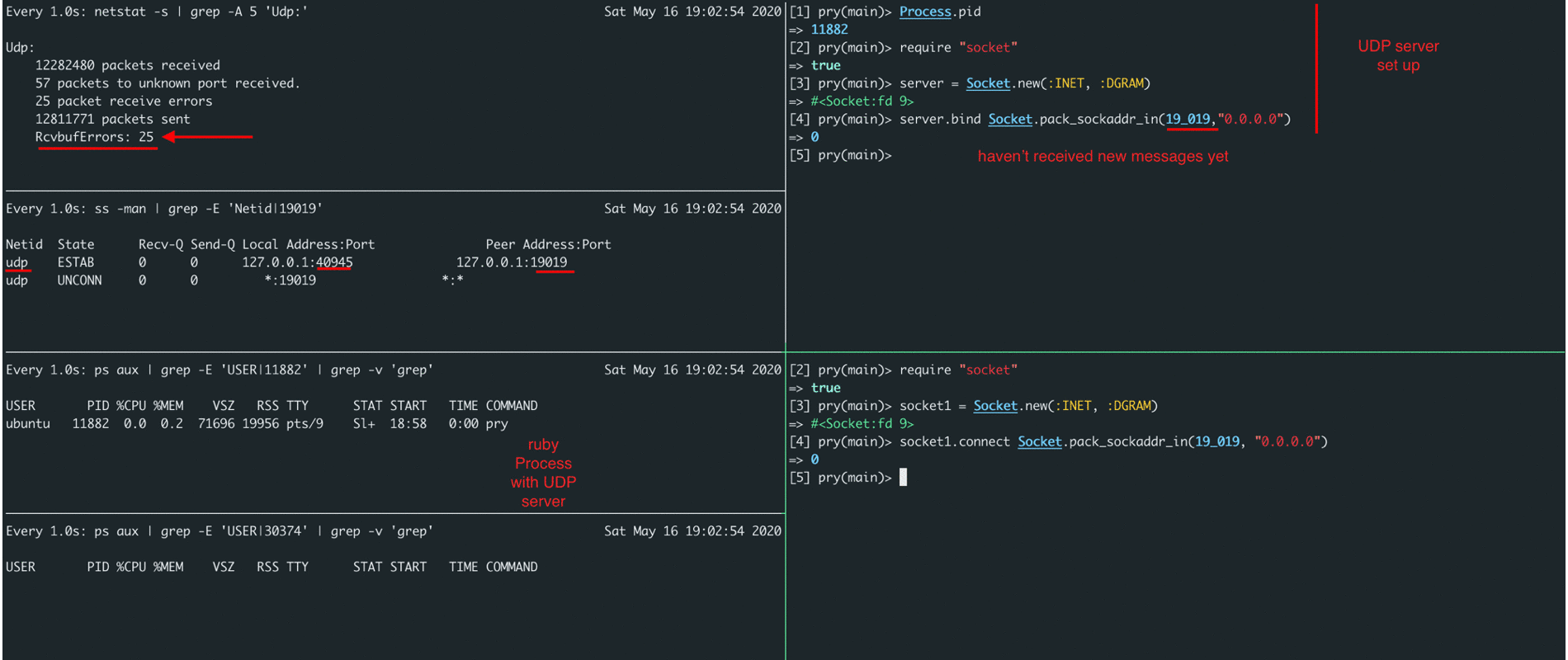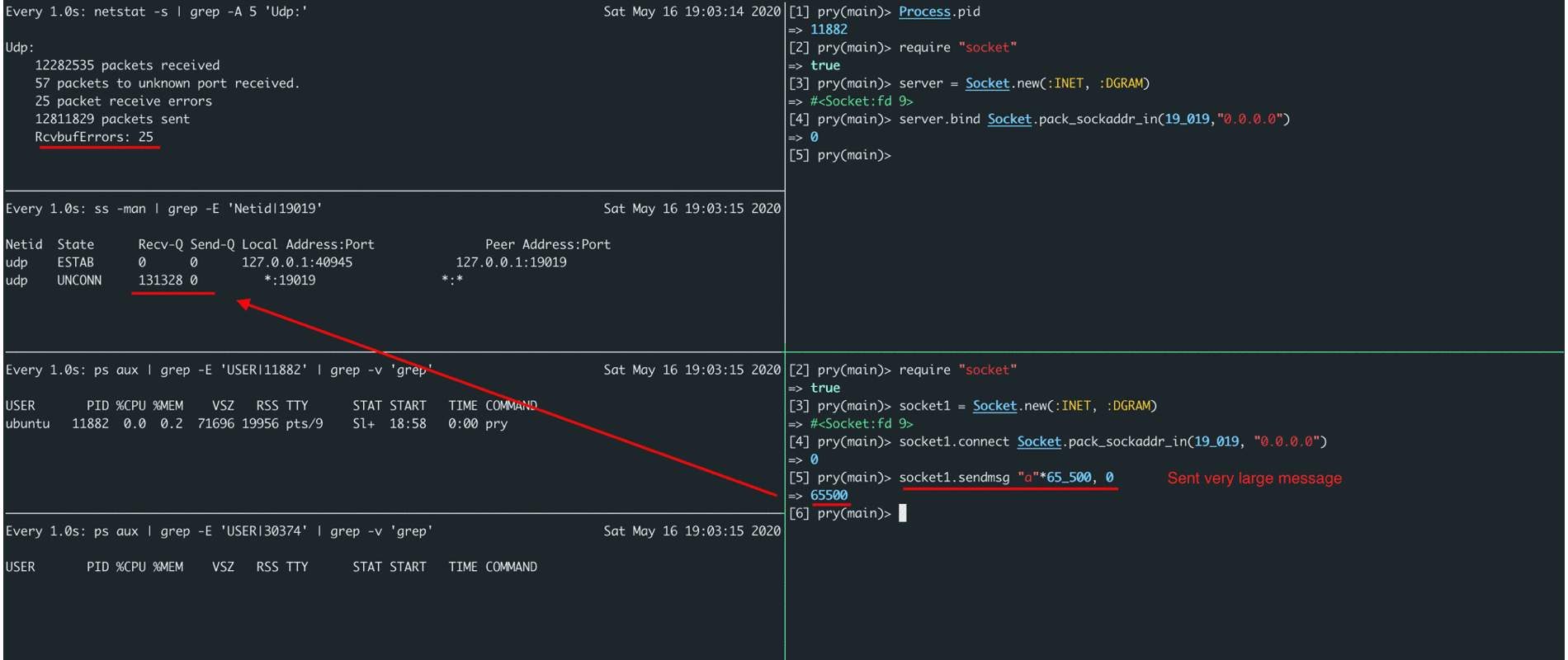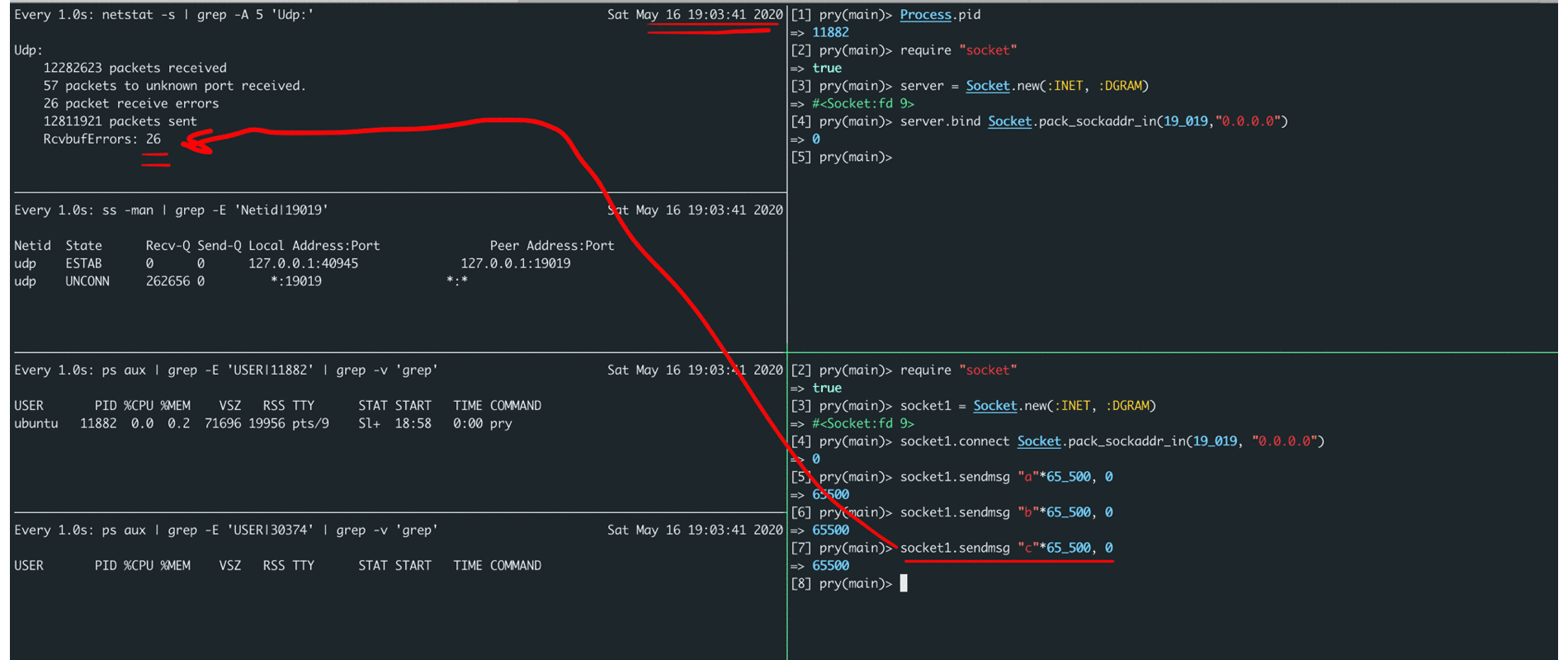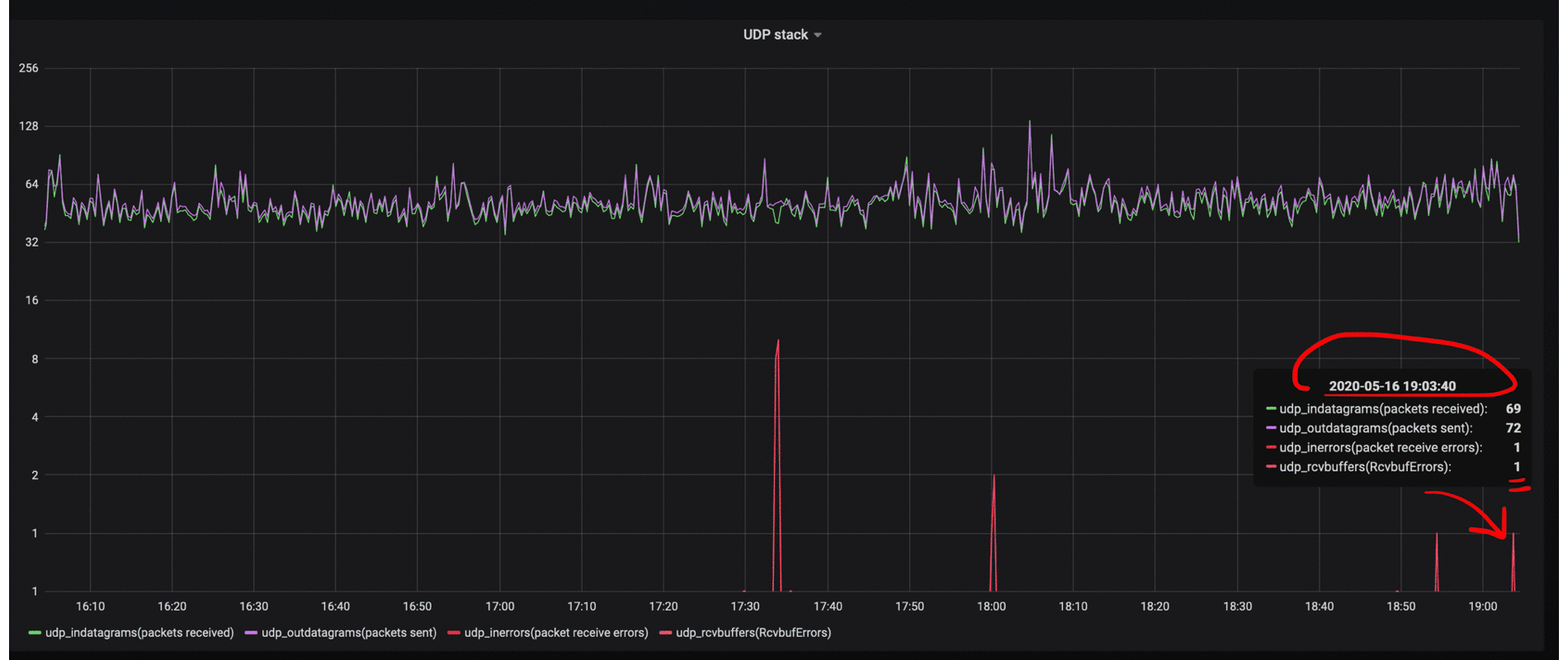
By adding monitoring metrics related to RcvbufErrors (packet receive errors), we could confirm our hypothesis that the issue was buffer overflows for storing incoming messages. How to increase it, many articles have been written and they can easily be found on the Internet by the name of the metric itself.
Raising the udp socket buffer, we achieved good results on receiving logs, and their losses became not noticeable to us.
And then we came across another message delivery protocol that was introduced in rsyslog.
RELP - reliable event logging protocol
In the TCP review at the beginning of this article, you could see that we sent 1_000_000 bytes, some of which reached the server, and some remained on the client. The server has not yet received the entire byte stream, but our client thinks that the stream has being processed by the server. What happens if one of the parties closes the connection at this moment? We will lose the message that we think has already been delivered. Those can be said with a small caveat about the reliability of message delivery in tcp - this is how rsyslog introduced a new protocol that makes sure message delivery to the server.
Conclusion
After reviewing and studying all the aspects that exist of TCP and UDP's use for log delivery, it becomes clear that while it is possible to do this task over the network using the application tools, however it seems not advisable. The reason? you would need to solve a lot of issues thus drastically increasing complexity of your application - there is something inside our almost monolithic application that would need to start managing and responding to all of scenarios:
- local buffers in memory
- connection management
- buffers on the disk
- buffer overruns, etc
And there will still be a window for possible loss of logs if all of this works inside Docker containers, for example.
Therefore, to reliably send logs inside the instance or between separate applications on different instances we opted to use a separate application - rsyslog in our case.
But here the question arises, how can we reliably send logs from the application to rsyslog within the same instance?
And I will talk about this in the next article.
Many thanks to our founder for his invaluable contribution to improving this article
