
Why is it that everyone always wants to get the most powerful things in the Universe? Petrolheads are dreaming of V8-powered vehicles. Any fast-growing economy wants to access unlimited nuclear energy. And Thanos wants to get ALL OF THE GEMZ!!
Most of these most powerful things have already been invented. Why we just can't use them? The answer is simple: as always great power comes with great responsibility and cost. Your V8 monster could easily make you bankrupt and that nuclear power plant, on the other hand, could potentially blow up and destroy everything you worked so hard to build.
So how could we keep everything we love but enjoy it in a more responsible way? In my experience, all of the things that show great performance in a responsible manner also shows great EFFICIENCY. Computing infrastructure is not an exception.
In this article, we'll try to figure out how much we could save on servers in the cloud. Not only in AWS. We'll try to apply efficiency patterns that we could see in nature onto the machines that are doing the work. Why? Because as we all know the mother nature itself is the most efficient thing in the universe.
Theory of efficiency
Any high load machine have a load pattern. In the most cases it looks like this function within the 24h period: \[ L\left(t\right)\ =\ \frac{l_{max}-l_{min}}{2}\left(\sin\left(\frac{2\pi t}{24}\right)+1\right)\ +\ l_{min} \]
Where \( t \) - time, \( l_{max} \) - maximal load, \( l_{min} \) - minimal load. Let's assume that our minimal load is 10% and maximal is 50%:
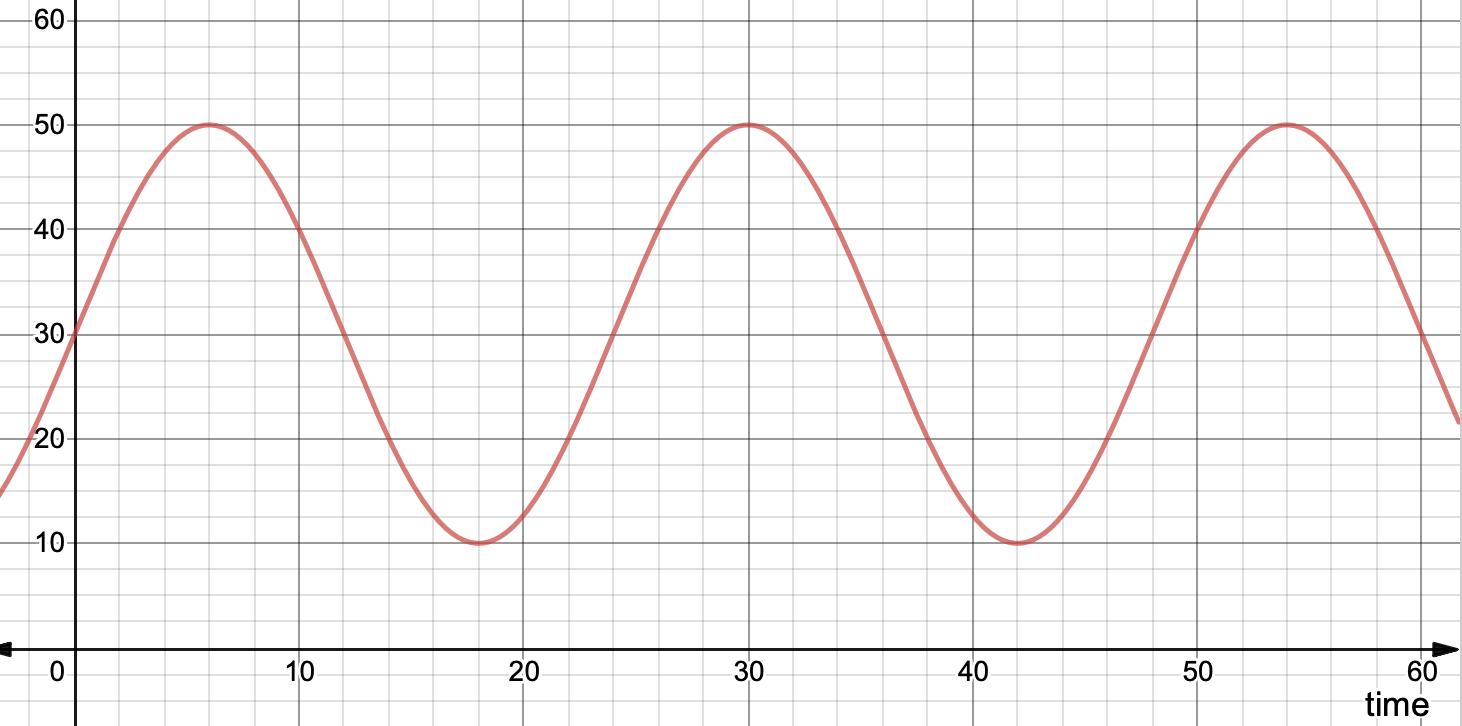
Okay, we have a cool chart now! So how could we measure the efficiency of the machine by looking at it? Just calculate an integral or the area below our function curve for the 24 hours. In this case we have: \[ \int_{0}^{24}L\left(t\right)dt = 720 (percent/day) \] Not bad.
But for sure we can perform a lot better and the solution is pretty straightforward: we just need to keep our minimal load as close as possible to the maximal to flatten the curvature of our pattern. We can achieve this by adding multiple machines that could switch on & off as and when they are needed. That's where automatic load regulation systems come into play.
Autoscaling is a good example of this kind of system. It's a typical negative feedback system which we could see everywhere in nature: population of any species and amount of feed, body temperature regulation and many others.
You just set desirable minimal load on your system and it will be trying to keep it at this level by changing number of machines.
From the other hand, we can increase the maximal load on the machines and distribute the load over time by using schedules and queues to make the pattern flatter. But not every type of load can be handled like this (users behaviour on websites or using APIs is unpredictable) but autoscaling also solves this problem anyway.
Let's make a full math model of how autoscaling works. The chart below shows how your load pattern changes with autoscaling and without. When the green dotted line (number of machines) is flat – we don't have autoscaling. It means that we're using 100 machines 24/7 turned on minimal load in 0% and efficiency of our system is still very low: \[ \int_{0}^{24}L\left(t\right)dt = 1020 (percent/day) \] But if we turn on the autoscaling we could see that our load pattern transforms to the machines number pattern as we are trying to keep the minimal load close to the maximal load and the load pattern becomes flat. In this case we have: \[ \int_{0}^{24}L\left(t\right)dt = 2040 (percent/day) \] The double efficiency of the system without autoscaling!
You could play with this model here: https://www.desmos.com/calculator/aqvy5ntdzd
For sure in the real-world scenario, we can't get a flat line in the load pattern and it can't be near 100% in some applications that require realtime and additional capacity. But even if we assume that maximal load of our pattern is 85% and minimal is 75% we've got 1920 (percent/day) efficiency and our system that still 1.88 times more efficient than the static system without autoscaling. This starts to save your money immediately.
Autoscaling also unlocks the ability to use spot instances feature without any limitations. Spots are something like "temporary machines". They could be turned on and off at any moment by AWS and they also cost approximately 1/3 of the basic on-demand machines. Autoscaling replaces terminated instances with new ones automatically when they have stopped working. And if we take the realistic number of 1.88 times saving from flattering load curve and apply 1/3 savings from spots we could get 5.64 times higher savings on the machines. If you have paid $1000 before you'll be paying only $177.30 by the time you have done all of this.
Looks like it is worth it!
What can we scale?
Calculations suggest that we can save a lot with autoscaling. But can it be used everywhere? Let's think about the standard architecture of a modern web application. We have API, background jobs, cache and databases. We can say that the load on all these components is subject to a periodic law and, therefore, it would be beneficial to apply autoscaling for everything. But autoscaling is not a silver bullet. Some things we can scale but some things we can not.
We at Sweatcoin do a lot of work in the databases. Horizontally scalable systems like CockroachDB and CitusDB supposedly work well with variable load and can easily handle the situation of adding or removing nodes. Looks good on paper ... We have tried many different technologies but our old buddy PostgreSQL continued to show the highest performance and stability.
Unfortunately, PostgreSQL cannot be easily and quickly scaled horizontally. So in our case, the only thing we can do is increase the server capacity. Or to distribute the load between shards ... but that's another story.
We use Redis as cache and KV-store. We have the same situation with it as with PostgreSQL. For this type of load, we can only apply a capacity reservation. To do this AWS has good Saving Plans that have been replaced with the Reserved Instances. On average these tools could save about 25% of our spending on large servers.
Anyway, the largest part of our spending is API servers and background jobs. The big advantage of these systems is that they are stateless and it is easy for us to change their number. We use the puma web server for API and sidekiq for background jobs. Allocating these services to a separate group of servers is the first thing that needs to be done to increase throughput and save on infrastructure even if you have to change the number of these servers manually to start with.
Scaling your server capacity scales your problems
In many promotional articles autoscaling is presented as magical mumbo-jumbo. One just has to turn it on and start saving tons of money. It's not very far from the truth. We have implemented it much faster than expected. But this only happened due to the fact that all the processes in the infrastructure were prepared for it. We can distinguish seven main points without which we would not be able to do this quickly:
- Terraform-driven cloud resources provisioning
- Ansible-driven server configuration & deploy
- Docker images building & delivery pipeline using CI
- Database connection pool
- Сonsul-driven service discovery
- Fine-tuned monitoring, logging & alerting systems
- Fast-reacting engineers with strong experience in troubleshooting backend problems
But even with such advanced technologies and talented engineers in your arsenal it is impossible to get rid of the catastrophic consequences that autoscaling can bring to your daily life.
In the matter of fact autoscaling automatically scales not only the number of your servers. It also automatically scales the number of issues and problems that have in your system. It is very important to understand this.
If you forgot to make a connection pool in your PostgreSQL then at peak load autoscaling will easily exhaust the connection limit. If you do not remove monitoring metrics from stopped machines then it will become very difficult to use your monitoring. If you forgot to check that your SMS delivery service is working at server start then in the morning you'll get a huge queue with stuck messages and a queue of angry users and managers. If for some reason when you start the server it will run on old version of your code dated a month ago then you run the risk of getting a strange hard-to-detect error which appears very rarely.
But do not be afraid of problems. The driver of all evolutionary changes is errors. Therefore on the way to efficiency you will stumble more than once and sometimes stumble upon the avalanche-like effects caused by the automation. All these problems will eventually allow you to build more and more efficient and reliable systems using an iterative approach.
Efficiency in action
When your infrastructure is well prepared you can begin with first phase of testing. We've decided to make a simple working concept on a system that permits failure at the very low cost. In our case this is a group of servers that serve the website https://sweatco.in
Of course it is not experiencing a very high load but it's enough to understand how to implement autoscaling anywhere.
This resource was typically served with the two most common c5.large instances. Two servers were used solely for fault tolerance if one of them crashes.
At the initial stage, we decided to simply create the disk image from one of the working servers. You can do this in the EC2 web console by performing the following for the server concerned Actions > Image > Create image. After that, you need to think about what will happen next when the virtual machine starts from this image and what you must change or setup. The obvious steps here are:
- Generate a unique and human-readable hostname
- Delete all the data from the machine containing the old hostname
- Update the version of the application code and run it
Now it's time for bash-scripting! We've collected all this stuff into a single file and decided to use it as a cloud-init configuration. This script will be executed automatically when the virtual machine starts:
#!/bin/bash
systemctl stop sweatcoin-frontend telegraf rsyslog consul
rm -rf /var/consul/*
docker pull sweatcoin-frontend:latest
sed -i 's/[a-f0-9]\{40\}/latest/g' /etc/systemd/system/sweatcoin-frontend.service
systemctl daemon-reload export
NEWHOSTNAME=$(hostname | sed 's/-/ /g' | awk '{ print "static" $4 $5}')
hostnamectl set-hostname $NEWHOSTNAME
echo 127.0.0.1 $NEWHOSTNAME >> /etc/hosts
systemctl start sweatcoin-frontend telegraf rsyslog consul
We use systemd and docker to run applications. The first step is to stop all services on the server as they may contain old code. Ideally, you should stop all these services before creating an image of a virtual machine and, moreover, run a command to prevent these services from starting automatically at startup:
systemctl disable sweatcoin-frontend telegraf rsyslog consul
Consul that we use for service discovery will not start if you change the hostname of your machine. Delete the directory that contains its state.
Updating to the latest version of our application. In our case, the application is packaged in docker image and the last build is additionally tagged with the latest. We intentionally hid the full name of docker image for security reasons, since it contains the address of our registry in which it is stored. Registry is essential part in code distribution pipeline so we've decided to use well-known and secure AWS Container Registry. This is a fairly stable and easily configurable system that allows you to distribute docker images across hundreds of servers inexpensively and quickly.
Then we replace the 40-character git SHA with which we tag all of our builds and replace it with "latest" with simple sed one-liner. Autoscaling starts up machines with horrendous hostnames like ip-192-168-3-55. This does not satisfy us, since in monitoring it is difficult to understand which group this server belongs to. Therefore, we rename it in our case from ip-192-168-3-55 to static355 using the last numbers of the IP address from the old hostname.
Finally, the last step, we launch our services with:
systemctl start sweatcoin-frontend telegraf rsyslog consul
Now we are ready to create a new Launch Configuration in EC2 using the previously generated image and shell-script and try to run the Autoscaling Group from it. At first, you can just try to configure this manually, but if as in our case you plan to do a lot of autoscaling groups then it’s better just create and edit them through terraform:
resource "aws_launch_configuration" "static" {
image_id = "YOUR_AMI_ID"
instance_type = "c5.large"
security_groups = [aws_security_group.generic.id]
user_data = file("autoscaling/static.sh")
spot_price = "0.05"
root_block_device {
volume_size = 32
}
lifecycle { create_before_destroy = true }
}
resource "aws_autoscaling_group" "static" {
depends_on = [aws_launch_configuration.static]
launch_configuration = aws_launch_configuration.static.name
desired_capacity = 1
min_size = 1
max_size = 5
vpc_zone_identifier = [aws_subnet.private.id]
target_group_arns = [aws_lb_target_group.static_http.arn, aws_lb_target_group.static_https.arn]
tag {
key = "Name"
value = "static_autoscaling"
propagate_at_launch = true
}
lifecycle {
create_before_destroy = true
ignore_changes = [desired_capacity]
}
}
resource "aws_autoscaling_policy" "static_cpu" {
name = "CPU"
autoscaling_group_name = aws_autoscaling_group.static.name
policy_type = "TargetTrackingScaling"
estimated_instance_warmup = 300
target_tracking_configuration {
disable_scale_in = false
target_value = 40
predefined_metric_specification {
predefined_metric_type = "ASGAverageCPUUtilization"
}
}
}Here we can see two configuration blocks that completely create Launch Configuration and Autoscaling Group with limits on the number of instances, as well as the last block containing the group scaling policy. In our case, we chose the simplest tactic - maintaining the CPU load at 40%.
It is worth adding that terraform will also allows you literally to connect the ALB load balancer with one line using the target_group_arns option.
Room to improve
We've managed to make the simplest autoscaling group which is already have started to save money and makes your infrastructure much more efficient.
As always it's just the tip of the iceberg. It is also necessary to monitor this system, configure deployment and clear old data from other systems. But perhaps the most important missing point here is the automatic building and testing of images before creating autoscaling groups based on them.
Later we will try to cover all these points in a separate articles. We will also try to cover how we came to the building of images using packer utility.
Stay tuned!
Special thanks to Oleg Fomenko for final editing!